What is Popsink? - Part 3/3: Enter Popsink
Part 3 - Enter Popsink
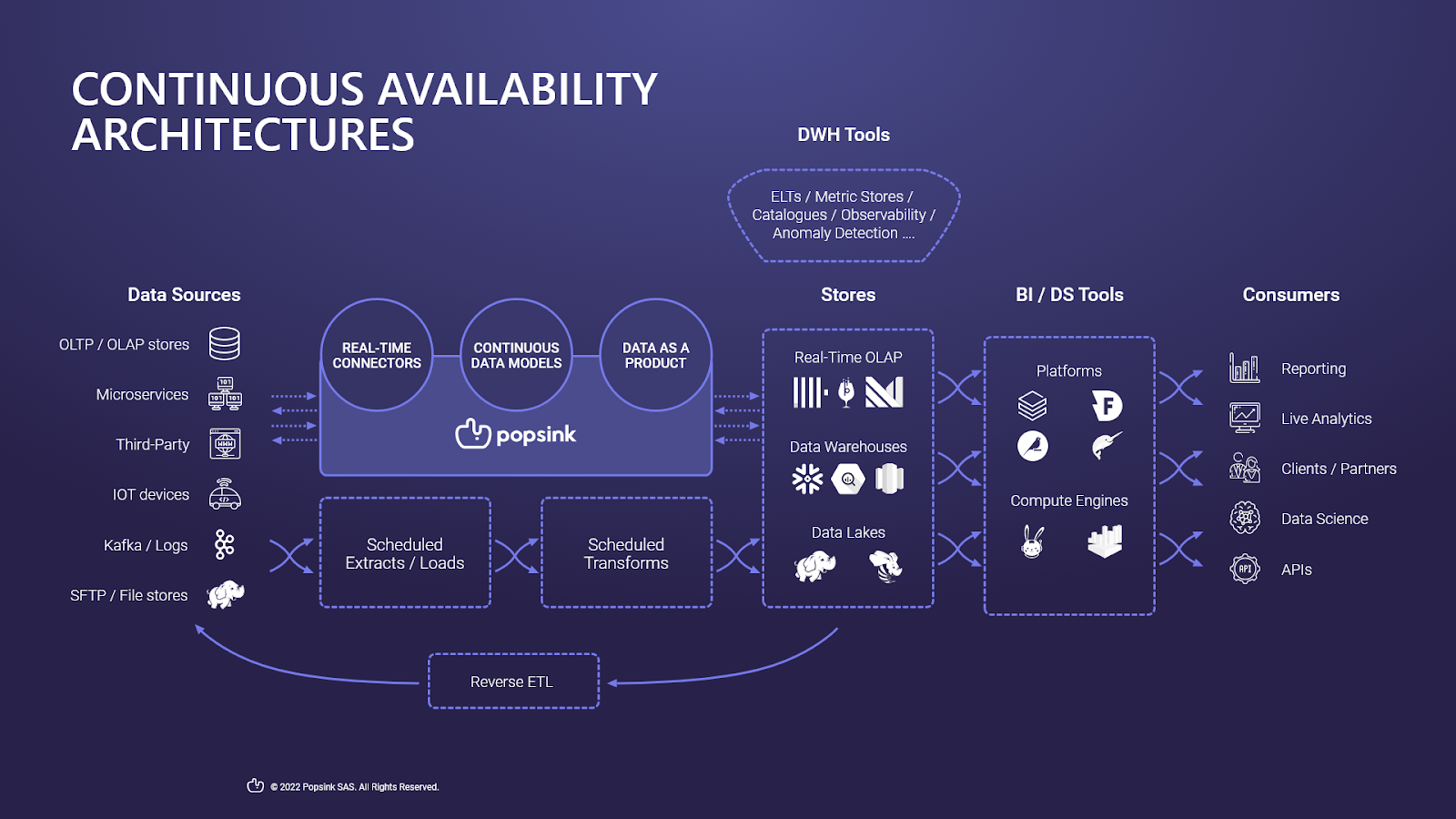
What changed?
Starting with the elephant in the room: there are now two types interfaces between sources and stores 1) the ELT/ETL services (which I could have merged with Reverse ETL) and 2) a continuous availability service (Popsink) 3) I've also replaced the "datamarts" in the Stores with Real-time OLAP examples. Although datamarts don't disappear at all, it felt like the significance of these services was now more worthy of highlighting - mostly for their ability to power your live and user-facing analytics. To talk architecture patterns: Popsink is a Kappa service so parallelizing it with your existing Batch pipeline gives you an out of the box Lambda architecture (a little more on this here).
What's the big deal?
As discussed in the previous part, there’s an unspoken 80 / 20 rule when it comes to data projects where the perceived benefit of just having a dashboard covers 80% of the use-case and data projects typically stop there - the rational is that once a human sees the data, actions can be taken and that's good enough. Automating these actions is a next order priority (that seldom materializes). This is because automation requires models to be built using an entirely different set of technologies with an adoption bar too high for the teammates used to conventional modeling pipelines.
Popsink bridges this gap between insights and actions by providing data teams with the missing piece in their Modern Data Stack.
As opposed to go-and-get-it, the transformed output comes to you. Tiny difference, massive consequences.
- First, since you no longer need to trigger a modeling process, this means that insights are available as source actions happen. No more 5am scheduling: data is modeled as it is produced and immediately reflected in downstream services, whether data stores (like your existing data warehouse) or operational services (like automation providers).
- Second, reusable models prevent redundant work between analytics and engineering teams: real time data is available to the business, business knowledge is available to systems and both can leverage the shared models for live insights and automation.
- Third: same tools! There's no migration needed with Popsink, the output is made available to your existing setup so you can supercharge your current Modern Data Stack without worrying about re-engineering any of it. Even better, you can basically copy paste your SQL code into Popsink and watch live data flow through.

Yesterday’s “good enough” is not today’s “good enough”.
Piloting businesses solely on daily excels and dashboards is no longer good enough to stay competitive in a microservices era. Yet, for all its misuses, Excel does one thing amazingly well: it allows non-technical users to automate at scale. Although Popsink's bar is a little higher (you have to know SQL), we enable the same capabilities for analytics engineering without relying on manual intervention. This kind of self-service operational capabilities create a competitiveness gap between businesses that can build repeatable, continuous and distributable data services and "dashboard organizations" that will continue to rely on reporting routines as point-in-time action triggers.
What now?
Popsink is currently running in pilots. If you're interested in becoming a tester and/or technology partner, send us an email with your use-case at [email protected] and come help us make slow data a constraint of the past.
